2023 iThome 鐵人賽
分享至
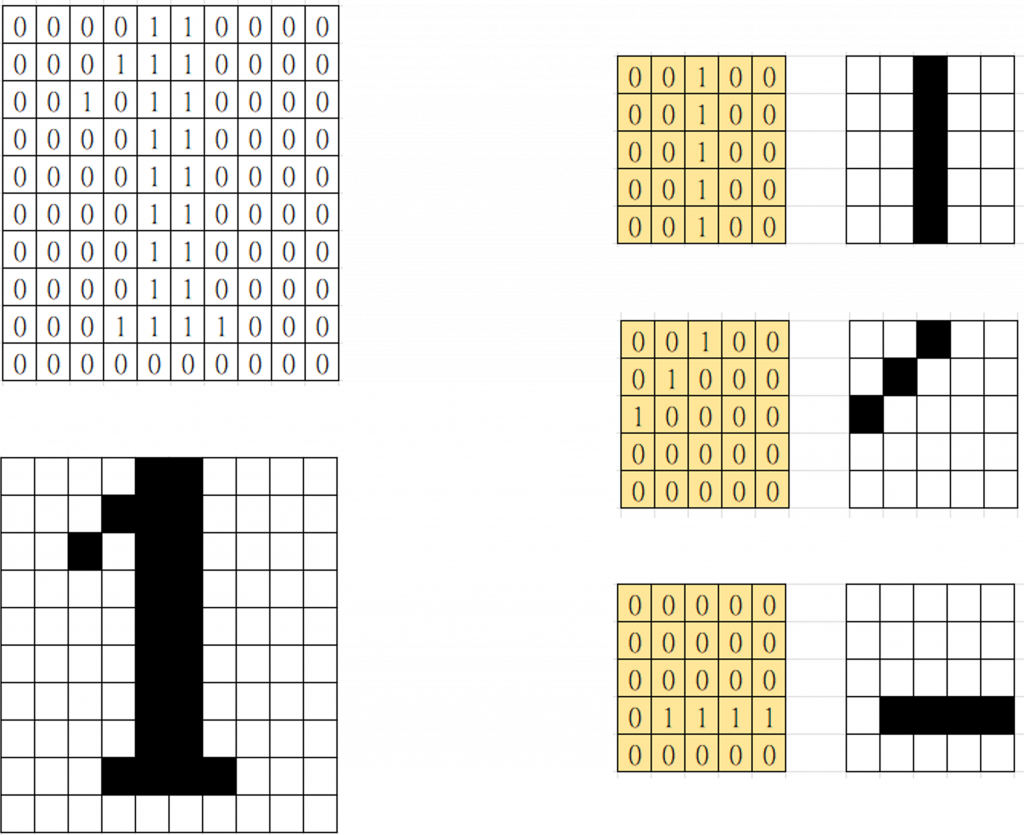
在電腦視覺或影像處理任務中,捲積(Convolution)是很重要的概念,可以幫我們獲得影像的特徵或相關性。用來處理影像的AI模型中也基於這樣的概念,誕生了許多捲積神經網路(Convolutional Neural Network)的架構,因此,在後續討論這些架構之前,今天,先讓我們來好好理解最基礎的概念吧!
IT邦幫忙


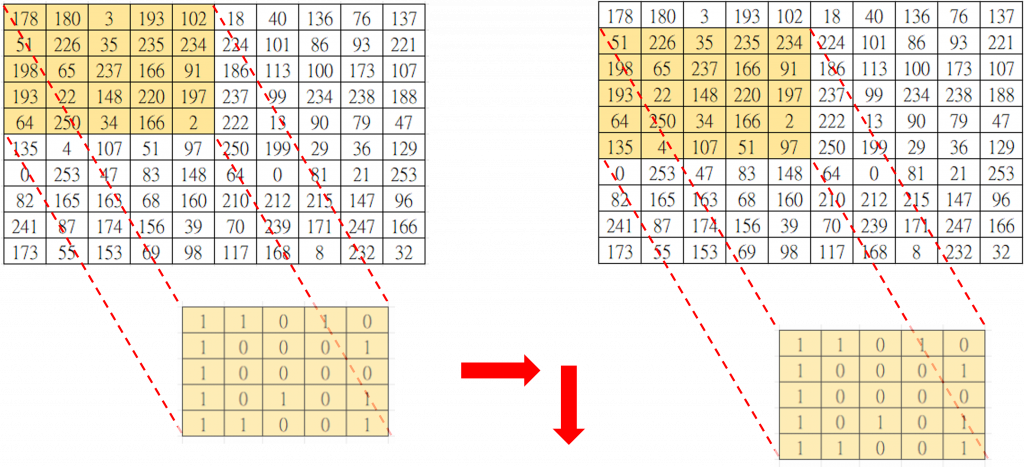 可以想像,經過這樣的過程之後,我們可以得到一張與輸入影像形狀相同但大小不同的「特徵圖」,這個特徵圖代表輸入影像中所有區域與橘黃色矩陣的相似程度。
可以想像,經過這樣的過程之後,我們可以得到一張與輸入影像形狀相同但大小不同的「特徵圖」,這個特徵圖代表輸入影像中所有區域與橘黃色矩陣的相似程度。